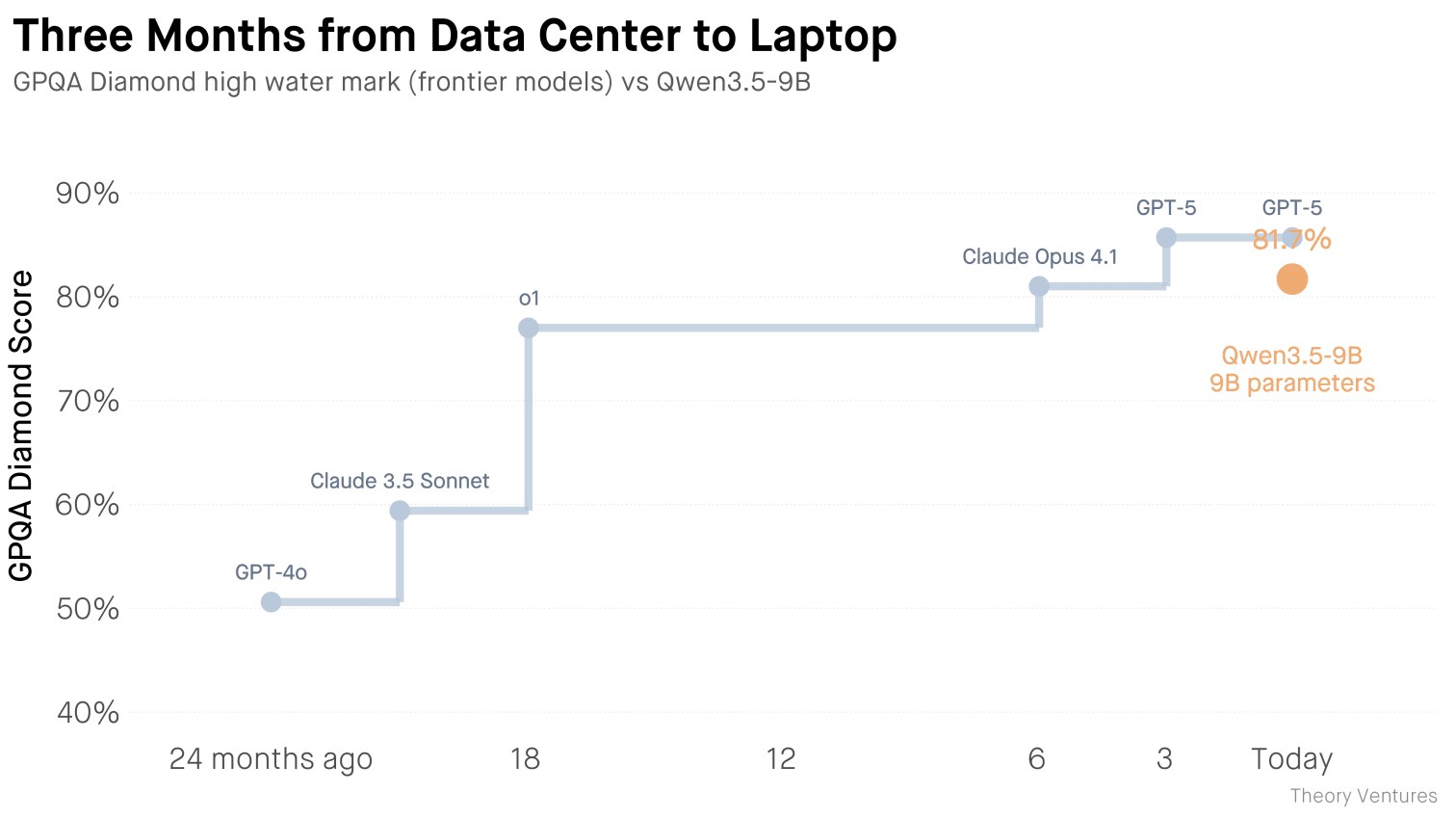
Alibaba has released the open‑source large language model Qwen‑3.5‑9B, a 9‑billion‑parameter system that fits into 12 GB of RAM and runs on a laptop costing roughly $5 000. At an average consumption of 20 million tokens per day, such “monster” models break even after about 556 million tokens – essentially within one month.
Public cloud APIs such as Claude or OpenAI charge around $9 per million tokens. With the same 20 million daily tokens, expenses climb to $756 per day, and on peak days they can surge to $720 per day when usage spikes to 80 million tokens. Shifting computation from a data center to a laptop rewrites the cost structure: instead of ongoing OPEX you incur a one‑off CAPEX expense, and variable costs shrink to electricity bills.
The technical trade‑off is clear. A laptop processes requests sequentially, while cloud platforms handle thousands of concurrent queries. For most small‑ and medium‑size businesses, typical workloads—drafting emails, summarizing documents, or generating code—operate in a one‑at‑a‑time mode. Queues can be scheduled for off‑peak night hours, and heavy scenarios can be spread over time.
What does this mean for business right now? Variable AI spend drops to the level of power consumption, eliminating dependence on third‑party providers. CEOs of mid‑size firms receive a clear signal: invest in laptop‑servers, cut OPEX tied to cloud APIs, and migrate repeatable tasks to an on‑premise environment.
Why this matters: The cost advantage turns AI from a variable expense into a capital investment that pays for itself in weeks. Reducing reliance on external APIs also improves data security and control. Executives can achieve predictable budgeting by allocating hardware budgets instead of tracking per‑token usage.